The "Friday Deployment" Disaster
Here is a scenario every Data Engineer knows too well. It’s Friday afternoon. The Product Team deploys a new feature. The app works perfectly. The customers are happy. But on Monday morning, the CEO logs into Tableau and sees the Revenue Chart flatlining at $0.
Why? Because the Product Team renamed a column in the database from cust_id to customer_uuid. It was a tiny change. But it broke the downstream ETL pipeline, the Data Warehouse, and the AI Forecast Model.
We call this “The Data Civil War.” Product Engineers optimize for Speed. Data Engineers optimize for Stability. Currently, the Data Team loses.
The Root Cause (Implicit Dependencies)
The problem isn’t the code. The problem is the architecture. Most data pipelines rely on “Change Data Capture” (CDC) or raw database scraping. Data Engineers hook into the backend database like a parasite. They “steal” the data without the Backend Engineer knowing.
When the Backend Engineer changes their database (which is their private implementation detail), they accidentally break the Data Team’s public interface. There is no contract. There is no agreement.
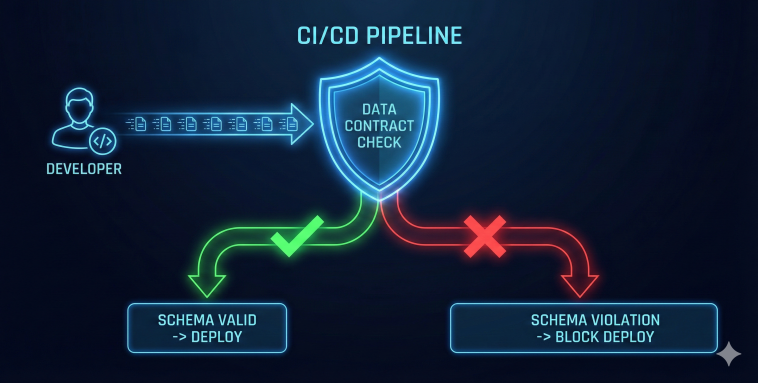
The Fix = Data Contracts
You don’t need better monitoring. You need Data Contracts. A Data Contract is a legal agreement (written in code) between the Service Producer and the Data Consumer.
Before data enters the pipeline, it is validated against a schema (e.g., JSON Schema or Protobuf).
The Rule: If a backend developer wants to change the data structure, they cannot just “push” it.
The Check: The CI/CD pipeline runs a check. “Breaking Change Detected: ‘cust_id’ is missing.”
The Result: The deployment is blocked until the contract is updated and versioned.
Is your pipeline fragile? How often do schema changes break your reports? Audit your reliability.
CDC is a trap. 🪤 You are hooking your analytics pipeline into the private implementation details of the application. When the app dev changes a column name? Boom. Your pipeline dies. 💥 The solution is Data Contracts. 🧵#DataScience #ETL #BigData #TechTips
Data as a Product
This shifts the mindset from “Data is Exhaust” (waste product) to “Data is a Product.” The Backend Team isn’t just responsible for the App; they are responsible for the Data API they expose to the business. When you treat data with the same rigor as microservices, the breakage stops.
Conclusion: Quality at the Source You cannot fix data quality in the warehouse (Snowflake/Databricks). It’s too late. You must fix it at the source. A contract prevents the garbage from ever entering the system.
Stop the Breakage Audit your upstream dependencies and schema governance.
Understanding that “Implicit Dependencies” are breaking your business is step one. Step two is enforcing a contract between your Service Producers and Data Consumers.
We use a proprietary Data Reliability Framework at GYSP to help enterprises move from brittle CDC pipelines to robust Data Contracts.
Stop fixing pipelines on Monday morning. Use the exact diagnostic tool we use with our enterprise clients to measure your Data Maturity.
👇 Take the Data Reliability Assessment Below: