The "Hello?" Problem
We have all been there. You call a customer support line. You say: “I need to check my balance.” … (Silence) … … (Silence) … You say: “Hello? Are you there?” Bot: “Sure, I can help with that.”
The conversation is broken. In the world of Text, latency is an annoyance. In the world of Voice, latency is an Outage. If your Voice AI cannot respond in under 800 milliseconds, the illusion of intelligence breaks.
The Math of Slow (Why HTTP Fails)
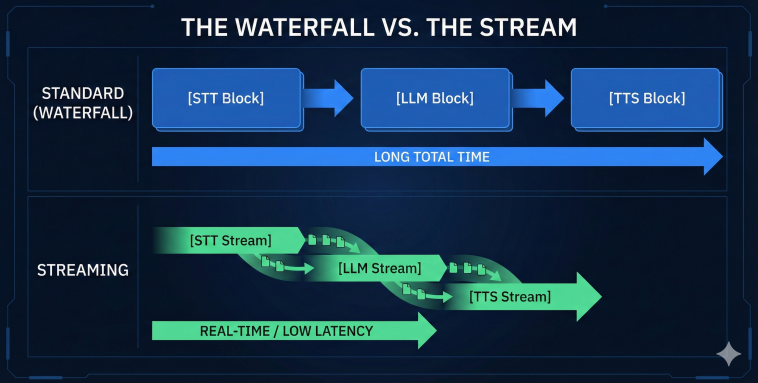
Why is it so hard? Because a standard “Request/Response” architecture adds up.
Speech-to-Text (STT): 1.0s (Wait for user to finish sentence -> Transcribe).
LLM Processing: 2.0s (Wait for full generation).
Text-to-Speech (TTS): 1.5s (Generate audio -> Play). Total Latency: ~4.5 seconds. This is unacceptable. Humans naturally pause for only 0.2 to 0.5 seconds.
The Fix = Streaming & WebSockets
To fix this, we must abandon REST APIs and embrace WebSockets. We need a Bi-Directional Stream.
Streaming Input: We don’t wait for the user to finish the sentence. We transcribe audio chunks in real-time.
Streaming Inference: The LLM starts generating the answer while the user is still finishing their thought (Speculative Decoding).
Streaming Output: We play the first chunk of audio (TTS) the millisecond it is ready.
This brings latency down from 4.5s to 500ms.
Is your Voice AI too slow? Calculate your current pipeline latency and where you are losing time
In Text, latency is an annoyance. 🐌 In Voice, latency is an outage. ❌ If your AI takes 3 seconds to respond, the human will start talking again. To fix this, we must abandon REST APIs and embrace Streaming. 🌊 Read the Full Strategy + Get your Score. #VoiceAI #Latency #WebSockets
The Interrupt (Barge-In)
Speed isn’t the only problem. You also need “Barge-In.” If the bot is talking and the user interrupts (“No, wait!”), the bot must shut up immediately. This requires VAD (Voice Activity Detection) running on the Edge, not the Cloud. If you can’t handle interruptions, you aren’t building a conversation; you are building a lecture.
Conclusion: Speed is a Feature In 2026, AI Intelligence is becoming a commodity. Everyone has GPT-4. Speed is the differentiator. The winner isn’t the smartest bot. It’s the one that replies fast enough to feel human.
Audit Your Architecture Are you stuck on HTTP? Move to Real-Time.
Understanding that REST APIs fail in Voice is step one. Step two is mapping your exact end-to-end latency to find the bottlenecks.
We use a proprietary Voice Architecture Framework at GYSP to help enterprises move from slow, sequential HTTP calls to real-time WebSocket streaming with instant “Barge-In” capabilities.
Stop making your customers wait in silence. Use the exact diagnostic tool we use with our enterprise clients to measure your Voice AI maturity.
Take the Voice Latency Assessment Below 👇