The Hand-Off Nightmare
It is a story told in engineering departments across the world. Your Data Science team just spent three months building a brilliant Generative AI model. It accurately answers queries, summarizes documents, and runs perfectly on their local laptops.
They package it up, toss it over the wall to the DevOps team, and say, “Ready for production!” Then, the project stalls for six months. Why? Because of the “It Works On My Machine” AI Crisis.
The Local Illusion
When Data Scientists build AI models locally, they often test them against static, perfectly clean CSV files or tiny local databases.
But DevOps lives in reality. DevOps has to connect that AI model to the company’s live, messy, constantly updating production data. If your architecture relies on pushing transactional data into a standalone, third-party Vector Database, DevOps now has to build custom ETL pipelines just to keep the AI fed.
The Vector DB Roadblock
The friction isn’t the AI model itself; it is the infrastructure required to host it. When DevOps tries to scale a model that relies on fragmented databases, they face:
Latency: Querying a primary database, moving data, and querying a vector database takes too long for real-time user applications.
Sync Failures: If the pipeline breaks, the Vector DB goes out of date, and the AI starts hallucinating outdated information.
Rollback Nightmares: If an AI deployment goes wrong, rolling back the model is easy, but rolling back synchronized vector data across two different cloud environments is nearly impossible.
"It works on my machine." 💻📉 Your Data Science team built a brilliant model locally, but when handed it to DevOps, the whole project stalls for 6 months. Here is why? Read the Guide & Get your MLOps Score 🧵#DevOps #MLOps #DataScience #AI
The Unified Standardization
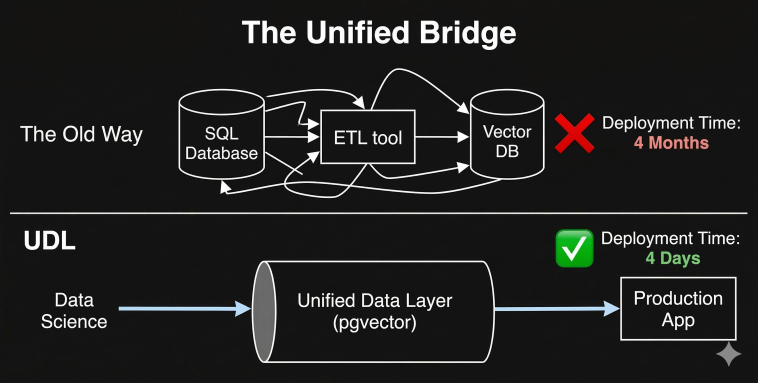
The solution to the MLOps crisis is standardizing the environment.
By utilizing a Unified Data Layer (like PostgreSQL with native vector support), Data Scientists and DevOps are finally speaking the same language. The Data Scientist builds the model using the exact same database architecture that DevOps will use to host it.
No new ETL pipelines to build. No third-party SaaS tools to secure. Just a smooth, frictionless deployment.
Conclusion: Stop Tossing Models Over the Wall If your AI projects are taking months to move from prototype to production, your DevOps team isn’t slow—your infrastructure is broken. Standardize your data layer, and watch your deployment bottlenecks disappear.
Understanding that fragmented infrastructure is killing your AI deployment speed is step one. Step two is giving your Data Science and DevOps teams a standardized environment where models can scale without friction.
At GYSP, we use our proprietary Unified Data Architecture to eliminate the MLOps hand-off nightmare. By consolidating your embeddings into your primary relational database, we help enterprises completely bypass the need for custom ETL deployment pipelines, allowing DevOps to launch AI products in days, not months.
Stop letting brilliant AI models die in production. Use the exact diagnostic tool we use with our enterprise clients to measure your team’s deployment readiness.
Take the MLOps Deployment Scorecard Below 👇


