Once you have clean text, don’t just split by math. Split by Meaning. Semantic Chunking uses an embedding model to measure the “topic similarity” between sentences. If Sentence A and Sentence B are about the same topic, keep them together. If Sentence C starts a new topic, create a new chunk. This ensures the AI always gets a “complete thought” in its context window.
Conclusion: Respect the Source Data Engineering for AI isn’t just moving files from S3 to Pinecone. It is about preserving the meaning of the source material. If you feed your AI broken chunks, don’t be surprised when it gives you broken answers.
Audit Your Pipeline Stop guessing. Start parsing.
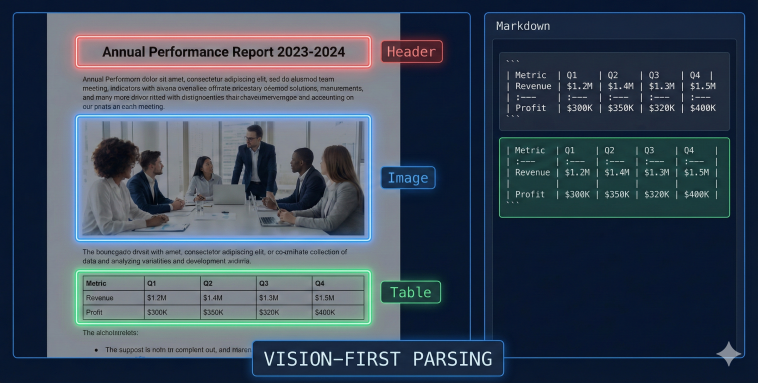
Understanding that naive chunking causes hallucinations is step one. Step two is migrating your ingestion pipeline to a Vision-First, layout-aware architecture.
We use a proprietary Unstructured Data Framework at GYSP to help enterprises parse complex PDFs, preserve table structures in Markdown, and implement semantic chunking to protect context.
Stop shredding your documents. Use the exact diagnostic tool we use with our enterprise clients to measure your ingestion maturity.
Take the Unstructured Data Readiness Assessment Below